Build Azure Synapse data Warehouse
Securely and Swiftly
Leverage the full potential of the next-gen cloud data warehouse, Azure Synapse, with the industry’s leading data solution Lyftrondata. Get a managed and cost-effective solution with columnar data storage, massively parallel processing (MPP), efficient integration, and actionable insights.
Load your data into
Azure Synapse instantly
Lyftrondata Pipeline manages connections to data sources and loads data to Azure Synapse Data Warehouse. All transformations are defined in standard Synapse and pushed down to data sources and Azure Synapse Data Warehouse. Lyftrondata eliminates traditional ETL/ELT bottlenecks with automatic data pipeline and make data instantly accessible to BI user with the modern cloud compute of Spark & Snowflake.
Lyftrondata connectors automatically convert any source into normalized, ready-to-query relational format and provide search capability on your enterprise data catalog. Lyftrondata shortens data preparation activities by letting data teams create logical data sets first, evaluate the data and delay the data loading until the data sets are verified or data loading is required.
Eliminate the complexity with Lyftrondata's simplicity
Velocity 1000+
Parallel Auto Data Warehouse
Speed
75%
Faster results to insights
Cost
60%
Reduction in
cost
Time
200X
Faster
migration
Density
100X
Faster business
decisions
Simplicity
1500X
Faster
learning
Why choose Lyftrondata for Azure Synapse
Integrate your data with Lyftrondata instantly and blend with 300+ other sources
Data extraction with Lyftrondata is easy. Be up and moving in minutes. Without any help from developers, Lyftrondata enables you to choose your most valuable data and pulls it from all your connected data sources in just one click.

Business Analyst
I feel more aligned with the agile process as now I can analyze any data without worrying about any technical know how.
Empower your analytics with an out-of-the-box relational data model
Connect any API, Json, XML and automatically analyze it with ANSI Synapse and load it to Azure Synapse. Once the data is extracted, you could ingest it to the Azure Synapse or BI tool of your choice with zero coding required.

Data Analyst
I have a better control on the data analysis process as now I can run rapid fast queries against the API’s which I never thought possible.
Built for the agile data culture for your data
Next, analyze massive volumes of this real-time data in visualization tools and get instant answers to your store performance. Over 100 integrations empower you to use your favorite tools to map data, build and visualize custom reports and more.

Data Architect
I am able to do the architecture and requirement gathering by simply writing ANSI Sql queries for the API sources which use to be the taboos for me.
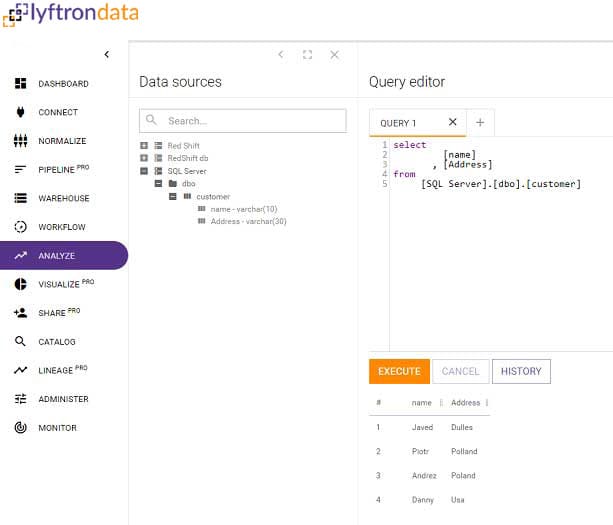
Load your data into your warehouse or lake instantly
Transform your growth metrics by combining your data and your delta automatically. Joining tables, renaming metrics and mathematical calculations result in a deeper and more complex data structure than the raw data.

ETL Developer
I am able to build my data pipeline in few clicks and load billions of records to my warehouse and also able to do cross platform joins on the API sources with ease.

Analyze your data from any BI/ML tools
Build delta lake on the Azure Synapse and save thousands of engineering hours and significantly reduce the total cost of ownership. The platform handles all the infrastructure development, empowering users to skip engineering work and go straight to analysis.

BI Analyst
I have a better response from the BI reports and able to connect with API/Json/XML based sources in just fewer clicks.

Data sharing is data caring
Define, categorize and find all data sets in one place. Share these data sets with other experts through APIs and drive better insights and user experience. This data sharing ability is perfect for companies who want to store their data once, share it with other experts and use it multiple times, now and in future.

Our agile team
We are in full control of our data exchange process and easily able to share the data instantly and collaborate with teams with ease without worrying about writing complex API, FTP, Email for data sharing.

Features

Codeless development
Allows users to Integrate all types of data without writing any code through a codeless development environment increasing developer productivity.

High-speed performance
High speed performance – the technology does not work on data row by row like traditional ETL products, but does so in set and bulk operations.

Comprehensive analytics
Access advanced reports for better insights on your Azure Synapse Database Warehouse data. Get insights across products, channels, customer lifetime value, and more.

Lower infrastructure
costs
Control the existing power of DBMS hardware engines, rather than depending on external staging servers & scale with ease.

Prebuilt transformation templates
Use default templates for common transformations like Star Schema and integration techniques eliminating time spent on tedious tasks.

Complex data parsing capabilities
Complex Data Parsing capabilities are built into the tool – Access and parse complex data types including Web logs, JSON and XML files.

Business intelligence
Connect any BI tool using build-in Synapse Server drivers through a fully simulated Synapse Server protocol. Bridge a connection from SaaS BI tools to on-premise data and the on-premise Enterprise Data Warehouse.

Performance and effectiveness
Experience high-speed performance, as Lyftrondata architecture does not process the data row by row, like traditional ETL products, but performs set and bulk operations in a single go.

Secured access
Maintain protected and resiliency against constant cyber threats
through our secured Lyftrondata architecture.
How to get started with Lyftrondata team?
Step 1: Assessment & advisory
Start a short Azure Synapse PoC to find out which workloads would benefit from migration. Our Advisory services enable a smooth transition.
Step 2: Data migration & replication consultation
Consult with our experts on how to liberate your data from legacy databases with our trusted cloud migration solution to Azure Synapse. We help you migrate from Netezza, Teradata, etc to Redshift.
Step 3: Modern data architecture support
Get endless support from our experts and modernize data pipelines for real-time data synchronization, using Data Vault 2.0, CDC, ELT to power your next-generation Data Lake.
Step 4: Data governance & data quality
Our solution and experts help accelerate data governance modernization and eliminate data silos that enable true reporting and proper data traceability.
Step 5: Analytics acceleration
Our solution empowers you to adapt the latest Azure Synapse trends which accelerate time to reporting and business application go-to-market.
Step 6: Round-the-clock training & support
Have your staff trained in the new tools and architecture of a modern data warehouse which enables the swift transition to your team.
Experience the power of the cloud with
our modern data ecosystem
Resources for data driven enterprises







FAQs
How Lyftrondata Works With Azure Synapse Data Warehouse?
Lyftrondata supports Lyft, Shift and Phase migration approach which enables enterprises to migrate from legacy platforms to Azure Synapse with ease and allows point existing database connection to Lyftrondata. Thereby, Lyftrondata acts as an intermediate layer until the migration is fully complete.
Lyftron Data Pipeline manages connections to data sources and loads data to Snowflake. All transformations are defined in standard SQL and pushed down to data sources and Snowflake.
Lyftrondata connectors automatically convert any source into normalized, ready-to-query relational format and provide search capability on your enterprise data catalog.
How is the data prepared for Azure Synapse migration?
Avoid needless delay in data preparation. Define virtual data sets on source data. Verify and load to Azure Synapse when required. Lyftrondata shortens data preparation activities by letting data teams create logical data sets first, evaluate the data and delay the data loading until the data sets are verified or data loading is required.
Any specific skill set required for Azure Synapse migration?
No drivers or new skills are needed to run queries on any data. Fully simulated Transact-SQL interface (wire compatible with SQL Server) enables bridged queries to Snowflake.
How is the data loaded in Azure Synapse?
Lyftrondata takes a unique approach to load data into Azure Synapse by utilizing the new data streaming API available in Snowflake. Data is loaded from the data source, data transformations are applied on the fly as SQL expressions and the transformed data is streamed directly to Snowflake. The data is loaded without any delays and without the need to manage any space for temporary files.
Additionally, Lyftrondata may push down selected SQL transformation directly to data sources to reduce the amount of data that must be transferred.
Do I need to generate an API for integration?
Not at all! Lyftrondata pre-built connectors automatically convert JSON and XML API to normalized structure and provide ready-to-query schemas and full search on data catalog.
Any specific size of data and BI tools supported in Lyftrondata?
Analyze any data size in more than 35 visualization tools! The agile-data delivery model could process trillions of rows, tables and delivers unmatched BI performance and limitless scalability for Azure Synapse users. Run real-time SQL queries on any data source. Create data sets and share them between teams and analytics tools.
How much time does it take to generate the dashboards in visualization tools?
The whole process right from the integration to produce actionable insights, happens in less than 4 minutes- promising a time optimization by 75%.
How does Lyftrondata promise secure access to my data like passwords, bank details, and more?
Lyftrondata enables enterprise-level security with a built-in security model and support for standard security frameworks and protocols. Its embedded security system allows data masking, field-level restrictions and architecture that automatically scales up and down.
Could I expect a consolidated dashboard produced from different data points?
Yes, absolutely! With Lyftrondata modern data pipeline, you could have an access to all your data points, make analysis simple for all stakeholders, and gain a holistic view of your Ecommerce store without any technical limitations.
What would be the process of data search in Lyftrondata?
Through a governed embeddable data discovery model, users can search, tag, alias, and enrich your data with ease. The powerful agile-based platform enables enterprises to transforms messy and unstructured data to facilitate and enhance their analysis.
How does Lyftrondata integrate logical data warehouse and data virtualization?
Lyftrondata modern data hub offers logical data warehouse where data is stored once and utilizes the memory compute for transformation, loading and standardization.
Data virtualization offer store users a single interface-often based on SQL-to access data in multiple places or formats.
Lyftrondata integrates data virtualization, manages the unified data for centralized security, and delivers real-time data for best class performance. Lyftrondata provides a common abstraction over any data source type, shielding users from its complexity and back-end technologies it operates on. It relies on views that allow Azure Synapse users to integrate data on the fly.
Which big data and cloud data warehouses could I use besides Azure Synapse?
Lyftrondata supports all the high performing big data warehouses like Hadoop, Spark, EMR, Azure, HDInsights, Databricks, etc. and next-gen cloud data warehouse like Redshift, Google Big Query and Azure SQL DW.
How is the migration governed in Lyftrondata?
Lyftrondata supports Lyft, Shift and Phase migration approach which enables users to rapidly modernize applications, migrate the right workloads, and securely manage their hybrid environment.
What would be the cost?
Please write to us at hello@lyftrondata.com for details related to pricing.
Would I have to write a manual data pipeline with Lyftrondata?
No, Lyftrondata will help you create Data Pipeline automatically and let you analyze the data instantly with ANSI SQL and BI tools.
Do I have to write a custom Rest job to connect with my API?
No, Lyftrondata will help you connect with your API and normalize your API JSON output automatically so you can focus on your business and Lyftrondata will take care of the data pipeline.
Do we need to create our own star schema and BI dashboard?
Lyftrondata is providing out-of-the-box data warehouse star schema design and BI dashboard for Ecommerce customers. So, you can just use our Ecommerce express solution to build your new analytics platform in no time.
Does Lyftrondata provide the pre-built pipelines from Azure Synapse to Stage & Stage to Data warehouse?
Yes, Lyftrondata will provide pre-built pipelines for Stage as well as Data Warehouse.
I keep on building data stores and data lakes which are resulting in data silos. How can Lyftrondata help me?
Lyftrondata will provide you with automatic data lineage and tags-based search which will populate our data catalog engine. So, anyone like business users, data analysts, or engineers can search all their objects with ease.
I have some custom JSON, do I need to convert them manually?
No, Lyftrondata allows JSON parsing function so, you can directly use simple select syntax and have your JSON data extracted quickly as shown on this query here
select JSON_PATH(LineAggregate, ‘$.[0].id’),JSON_PATH(LineAggregate,‘$.[0].variant_id’),
LineAggregate from
(select top 1 * from [Vertica].[Vertica].[Orders]) as orders
I have my data coming from CSV, S3, and Blob. Do I need to import the file metadata individually, and do I need to write a separate looping process to pull the files from subdirectories?
Lyftrondata will help you to automatically create the schema. It will do the auto-merging, auto-sync for your files, and auto-ingest into your target data warehouse. There is no need for any manual looping process, Lyftrondata will read the files from subdirectories automatically.
I don't want to give access to my data and pipelines to other users, how would Lyftrondata help me?
Lyftrondata has robust column-level security which will help you choose the access based on roles and user. Only the users you choose will get access to the pipeline, database, table, or column.
Do I need to write a custom pipeline to handle my incremental data?
No, you are fully covered with Lyftrondata auto sync feature which help you choose delta field, select the frequency and Lyftrondata will take care of the rest.

Satisfy your thirst for better data outcomes.
We’re here to listen. Tell us about your requirements. What challenges are you trying to solve?
