Data Pipeline: Purpose, Types,
Components and More
What is a data pipeline?
A data pipeline is a system that handles the processing, storage, and delivery of data. Data pipelines are used to extract insights from large amounts of raw data, but they can also be applied to handle other types of tasks. The benefits of using a pipeline include faster processing times, greater scalability for new datasets, and better security for stored information. In this blog post, we will discuss what a pipeline is, its different types as well as standard components, and why you should use the system.
A data pipeline is a series of steps that are performed on data. These steps can include transforming, cleansing, aggregating, and cleaning the data to make it suitable for analysis or modeling purposes.
A data scientist may use one as part of an ETL processor to prepare the data before running an analysis on it. This way they don’t have to waste time creating their own while solving critical business challenges.
Data exploration – Before you start creating models or doing analysis, the data must be analyzed and cleaned up to ensure there are no errors in your dataset. This can help save time when modeling/analyzing because you will not have any “bad” data points which could lead to inaccurate results. It also ensures clean output for reporting purposes so anyone who reads reports based on this information will get accurate numbers.
Transparency – When dealing with multiple analysts within an organization, having a documented process of how certain types of data need to be treated before being used by various teams. This allows everyone to know exactly what steps were taken on the dataset and what assumptions they should be aware of when using this information.
Governance – Having a standard process/procedure for data management can help to ensure that there is no loss or unapproved changes to the dataset.
Balancing IT users and data analysts with governed analytics and discovery
Different types of pipelines
Simple dataset
This type usually involves simple fields such as names, addresses, and phone numbers which do not require any cleansing before they can be used in reporting/analysis.
Intermediate dataset
It includes more complex datasets which often contain multiple tables with many different types of attributes within each table (i.e., name, address, email, etc.). These datasets may also have various dependencies where one attribute needs another field from a different table to populate correctly.
Complex dataset
This type includes datasets with millions of records which often require a variety of processing steps before they can be used for analysis or reporting purposes (i.e., feature extraction, data quality checks, and so on).
Benefits of using a data pipeline
Processing speeds
A data pipeline allows the data to be processed in a much more efficient manner as it eliminates the need to wait till all the steps are completed before analysis.
Security
With everything being handled within one platform instead of various users working on different pieces and then trying to combine them, data security is greatly improved.
Access control
Each user person can view only datasets/tasks they are assigned to, which helps reduce the risk of sensitive information being released to unauthorized personnel.
Collaboration
Data pipeline allows multiple users to work on different pieces without having any overlap or conflict with each other. This saves time and makes it easy for users to interpret what someone else has already done before starting their analysis.
Overall efficiency and agile approach
Data pipeline allows teams within an organization to work together more efficiently by allowing them to share resources such as code libraries, reusable components (i.e., Part-of-Speech tagging), and datasets in real-time. Users save a huge amount of time that would have been spent creating the pipeline. It’s very easy to use, and you don't have to worry about mistakes that might be made when building your own.
Data pipeline components
Data pipelines can be composed of various types of components which have their technical requirements and challenges to overcome when being implemented. A general structure for a typical data pipeline might look something like this:
Destination
The destination is the first consideration. It signifies where the data needed and why. Datastores – data warehouses, data lakes, data marts, or lake houses are common destinations of a pipeline. Applications may also be another destination for pipelines to take on tasks such as machine learning model training/applying etc.
Origin
Origin considerations are often driven by datastore design. Data should be where it makes the most sense to optimize transactional performance/storage cost or improve latency for near real-time pipelines. Transactional systems should be considered as an origin if they provide reliable and timely information needed at the pipeline’s destination(s).
Dataflow
Dataflow is the sequence of processes and stores that data moves through as it travels from source to endpoint. Dataflow is a part of an overall pipeline’s design process which involves much consideration when designing pipelines.
Storage
Storage refers to the systems where intermediate data persists as it moves through the pipeline and to the data stores at pipeline endpoints. Storage options include relational databases, columnar databases, key-value stores, document databases, graph databases, etc. The volume of data often determines storage type but other considerations can include data structure/format, duration of data retention, uses of the data, etc.
Processing
Processing refers to the steps and activities performed to ingest, transform, and deliver data across the pipeline. By executing the right procedures in the right sequence, processing turns input data into output data. Ingestion processes export or extract data from source systems and transformation processes improve, enrich, and format data for specific intended uses. Other common data pipeline processes include blending, sampling, and aggregation tasks.
Workflow
Workflow refers to the sequence of processes and data stores. Pipeline workflows handle sequencing and dependencies at two levels–the level of individual tasks performing a specific function, and the level of units or jobs combining multiple tasks. Data flows through pipelines in much smaller batches than it would when streaming from real-time sources. Some pipelines may only contain one task, while others may include many tasks connected by dependencies and data transformations to get from source to endpoint/destination(s).
Monitoring
Monitoring involves the observation of a data pipeline to ensure efficiency, reliability, and strong performance. Considerations in designing pipeline monitoring systems include what needs to be monitored, who will be monitoring it, what thresholds or limits are applicable, and what actions will be taken when these thresholds or limits are reached.
Alerting
Alerting systems inform data teams when any events requiring action occur in a pipeline. Alerting systems include email, SMS alerts, etc.
How Lyftrondata helps to transform your Snowflake journey
Data pipeline tools and infrastructure
A data pipeline is a set of tools and components that help you to effectively manage datasets and turn them into actionable insights. The ultimate goal is to use the information found within these datasets to make better decisions about business direction. A successful data pipeline can be divided up into nine main parts:
Batch schedulers
Scheduled tasks to execute scripts, send emails, copy data between databases, etc.
Data lakes
When a data lake is used to store and transform data for use in the pipeline, it may be necessary to put structure on unstructured files.
One option is to define metadata fields that can then be searched with SQL queries or other search methods such as regular expressions (regex) against text values. Another choice is putting all of this information into file-naming conventions so that scripts looking for specific types of structured/unstructured objects know where they’ll find them.
Metadata management tools like Lyftrondata enable users to bring their key-value metadata tags from relational databases using flexible scripting without having the need to write code.
Data warehouse
A data warehouse is often used as the final destination for data pipelines to store transformed, summarized, and aggregated datasets.
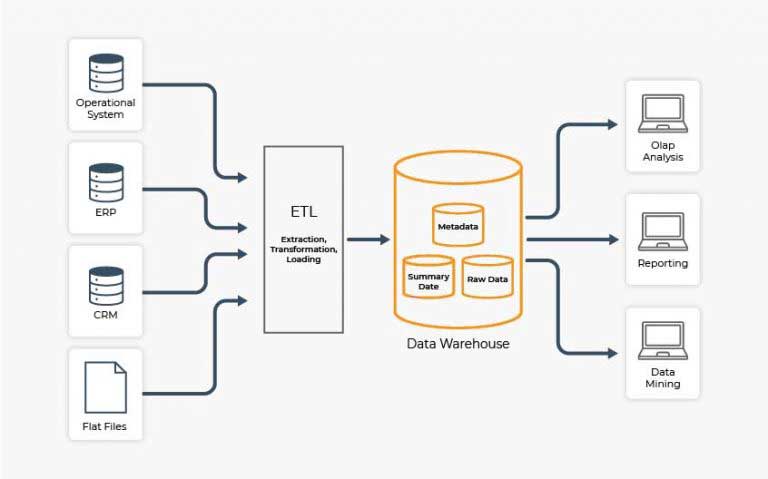
ETL applications
There are several open-source and commercial ETL applications available on the market which can be used to create data pipelines.
Programming languages
An ETL developer will need to use a programming language that’s easily accessible for the person writing the scripts. For example, SQL is often used to write pipeline tasks because it makes data transformation more straightforward and can be deployed on top of existing relational databases without needing an additional database installation. However, other languages like Python are becoming increasingly popular because they can be used to combine any type of data (structured, unstructured, or semi-structured) and interact with various databases.
Data validation tools
There are several open-source frameworks and commercial data validation tools available which check if the transformed dataset meets organizational requirements. For example, it may need to conform to regulatory standards like ISO or HIPAA.
Data masking tools
In the process of data validation, it’s often necessary to run a data masking tool on original datasets so that sensitive information is removed before being transferred into a new dataset. This prevents any real names or numbers from being exposed and enables users to test their processes with realistic but still safe-to-use data.
Kerberos authentication
For the highest level of security, Kerberos authentication can be used to ensure all system access is authorized and encrypted so that passwords are never sent across the network in plain-text form. This prevents unauthorized users from gaining access to any part of a production or development environment even if they manage to gain access.


Lyftrondata columnar ANSI SQL pipeline for instant data access
Many leading companies have invested millions of dollars building data pipelines manually but unfortunately were unable to reap the ROI. The result has mostly been a complex data-driven ecosystem that requires a lot of people, time, and money to maintain.
Lyftrondata removes all such distractions with the Columnar SQL data pipeline that supplies businesses with a steady stream of integrated, consistent data for exploration, analysis, and decision making. Users can access all the data from different regions in a data hub instantly and migrate from legacy databases to a modern data warehouse without worrying about coding data pipelines manually.
Lyftrondata’s columnar pipeline unifies all data sources to a single format and loads the data to a target data warehouse for the use of analytics and BI tools. Avoid re-inventing the wheel of building pipelines manually, use Lyftrondata’s automated pipeline to make the right data available at the right time.
How it works
Lyftrondata’s columnar pipeline allows users to process and load events from multiple sources to target data warehouses via simple commands. All data pipelines in Lyftrondata are defined in SQL. This concept enables scripting all data pipelines, and therefore there’s no need to build them manually. Data pipelines could be automatically scripted instead of building them manually in a visual designer. Get ensured that you can sync and access your real-time data in sub-seconds using any BI tool you like.

Are you unsure about the best option for setting up your data infrastructure?
