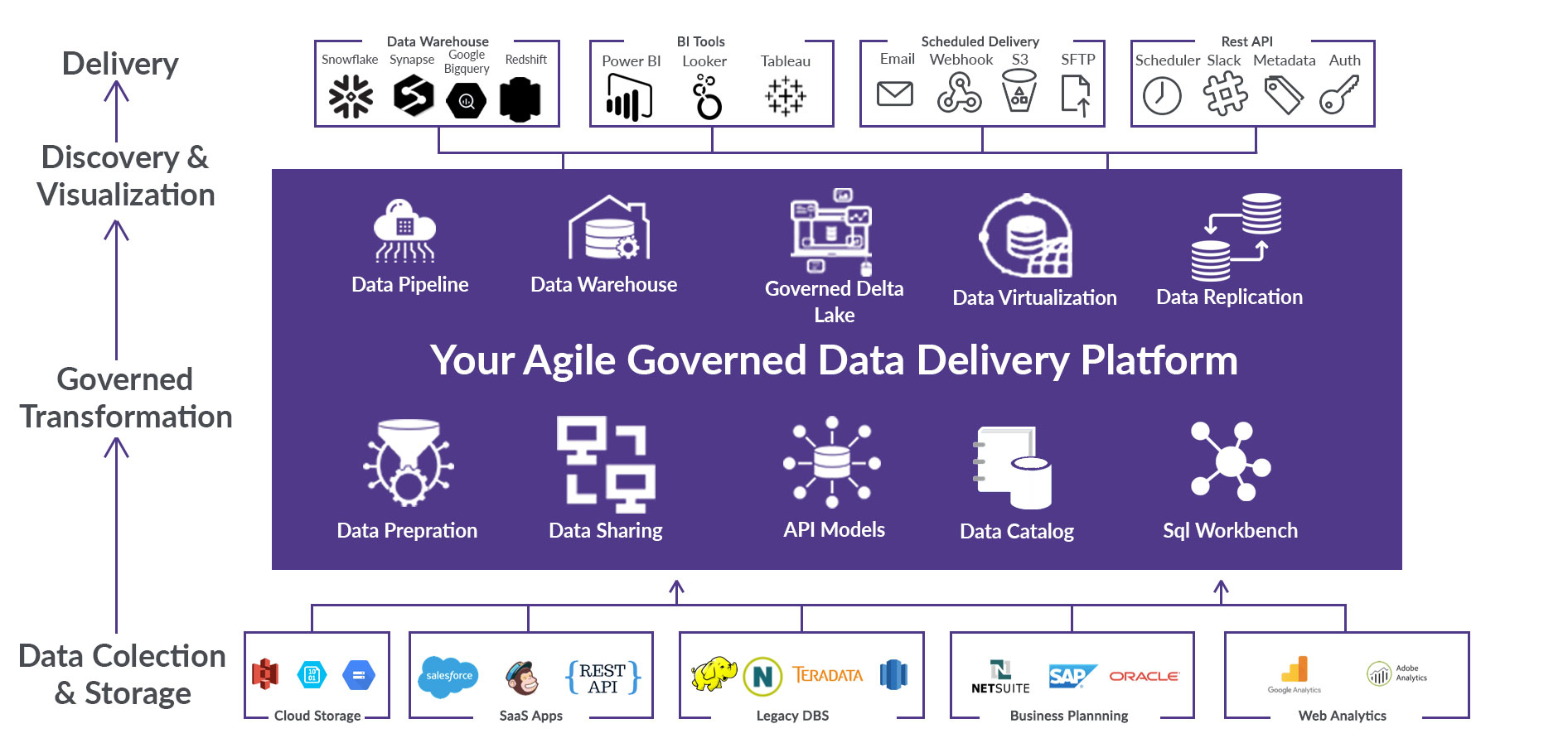
The next-gen modern data hub
Accelerate your time to trusted data with the 21st-century Lyftrondata hub. Do more with your data, get centralized control of ownership and sharing, move data at the right latency via a high-performance data pipeline, and get the finest control of your data management and operations.
Creating a centralized data hub
Lyftrondata is a Data Hub for analytics that is a central place to find all data, create shared data sets and manage data replication to a Data Warehouse in one place.
Lyftrondata is a central data hub for analytics that aggregates all source and target databases in one place. Lyftrondata is not just yet another ETL tool that loads data to another database. Lyftrondata’s architecture goes beyond and enables real-time SQL queries to data sources by simulating a database.
Eliminate the complexity with Lyftrondata's simplicity
Velocity 2000+
Data Warehouse Parallel Queries
Speed
75%
Faster Results To Insights
Cost
60%
Reduction In Cost
Time
200X
Faster Implementation
Density
100X
Faster
Migration
Simplicity
1500X
Faster
Learning
Lyftrondata pipes professional architecture
Automatic ANSI SQL pipeline.
Analyze data instantly with BI and ML tools.
Our connectors automatically normalized the data from API, Json and XML formats.
Real-time sync, data catalog, data lineage and data governance.

Innovative data sharing & unlimited cloud compute.
What you get

Query API data with SQL familiar syntax
With Lyftrondata, avoid creating time-consuming code and use your very own SQL to query any data, both structured and semi-structured. Its modern data architecture supports automatic zero code JSON/XML/API parsing to relational format. Analyze instantly with ANSI and make your data lake work for you. Lyftrondata's emulation of Microsoft SQL Server allows any client supporting connectivity to SQL Server to connect to Lyftrondata.

Emulation compatibility with SQL Server
Metadata model exposed by SQL Server, including metadata catalog, system views, stored procedures, and functions.
SQL dialect supported by SQL Server.
Tabular Data Stream network protocol as described in Microsoft TDS documentation.
Data types and conversions, where all data types are normalized automatically into equivalent SQL Server data types.
Secure your sensitive data with our encryption functions
Lyftrondata comes with a built-in enterprise data governance framework complying with all of the necessary rules and tools that your team needs to successfully operationalize your program. Amplify your information governance with a robust data lineage model that follows high-quality controls and governance mechanisms.

Easily auto-extract JSON, XML schemas into relational format
No need to write any complex API, rest services, JSON, and XML parsing jobs. Lyftrondata takes care of all these, it converts any data into a relational format and 'allows' you to query it with simple ANSI SQL.

Perform complex transformations
Skip writing long complex APIs, and transform instantly with SQL. Define data transformations as a standard SQL. Lyftrondata pushes down SQL to data sources and the cloud, making it easy for all users to access the information they need in a timely fashion.

Quickly apply complex joins
Apply high cardinality joins between API sources, S3, Blob and database, without heavily relying on the BI and data engineering teams to set up complex and time-consuming ETLs.

Easily query data from S3, Blob, JSON, Xml like a table
Eliminate traditional ETL/EDW bottlenecks by auto- normalizing API/JSON/XML/S3/Blob/NoSql sources into ready-to-query relational format. Focus on boosting the productivity of your data professionals and shorten your time to value.

Federate data sources like actual database
Take a leap from data federation technology and focus on performance optimization as well as self-service search and discovery. Spend more time analyzing data than searching for it.

State-of-the-art facial recognition API
Perform Azure cognitive AI access with our face recognition API function. Be on the top of technology, and use cognitive services that bring AI within reach of every developer—without requiring machine-learning expertise.
Lyftrondata easy-to-implement transformation functions supported for
Emulation delivers compatibility with the following SQL Server features:
Procedural programming constructs: IF, WHILE, DECLARE
Temporary tables (stored in memory).
Selected SQL session environment variables.
Security model supported by SQL Server.
Authentication using Windows Integrated Authentication and SQL Server Standard Authentication (Mixed Mode).
Job scheduling model and accompanying stored procedures.
Business benefits of Lyftrondata hub

Real-time analytics
Query all data sources with simulated Transact-SQL. Get real-time data from data warehouses or source systems during prototyping and data modeling.

Global data catalog
Describe all essential data sources and data sets in the data catalog. Use the self-service interface to find the right data.

Smart data pre-aggregation
Accelerate slow queries by materializing their results. Define pre-aggregates with joins, groupings and filtering that are 1000x smaller than original data. Turn any data warehouse into a virtual OLAP cube.

Instant in-memory analytics
Create a virtual data warehouse without even setting up a target data warehouse. Start with a single node build-in Apache Spark and scale it up to a whole Data Lake after measuring a required cluster size.

Data security
Transparently apply row-access security and dynamic data masking to any data source. Authenticate with Windows Integrated Security (Kerberos) from SQL Server when using any data source.

Data lineage tracking
Track down all data sets that will be affected by a change to a table or a column. Find out which source tables and columns are used in any data set, even if it is based on multiple other data sets.

Easily build end-to-end data pipelines for breakthrough results
