Understanding the
Star Schema
What is a Star Schema?
A Star Schema is a database organizational style that employs a single big fact table to store transactional or measurable data and one or smaller dimensional tables to hold qualities about the data and is ideal for a data warehouse or business intelligence. Because the fact table sits the middle of the logical diagram and the little dimensional tables branch off to create the points of the star, it’s termed as a Star Schema.
A fact table is the heart of a Star Schema database, and there is only one fact table per Star Schema database. The fact table lists the measurable (or quantifiable) primary data that will be studied, such as sales records, logged performance statistics, or financial data. It might be transactional, with rows being updated as events occur or a snapshot of historical data up to a certain point in time.
Experience a true Extract-Load-Transform with your familiar SQL and make your data lake as scalable and accessible as possible
How does a Star Schema work?
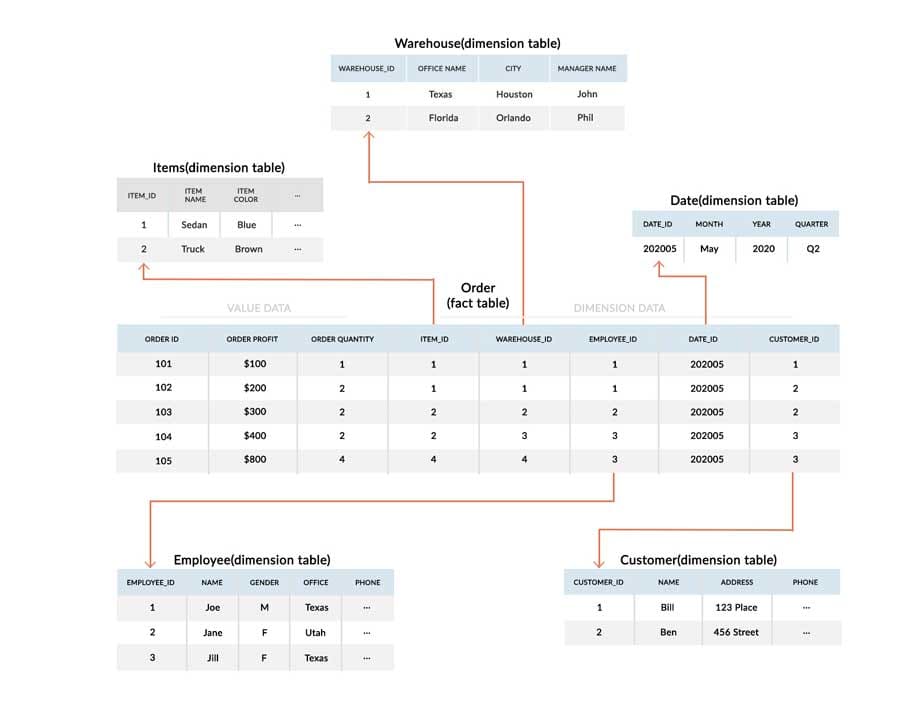
Numeric numbers and dimension attribute values are both stored in the fact table. As an example, consider the following:
Numeric value fields are unique to each row or data point, and they have no correlation or relationship to data in other rows. These might include transactional details like the order ID, total money, net profit, order quantity, or precise time.
The foreign key value for a row in a linked dimensional table is stored in the dimension attribute values, rather than data. This sort of information will be referenced in several rows of the fact table. It could hold the sales staff ID, a date value, a product ID, or a branch office ID, for example.
The fact table’s supporting information is stored in dimension tables. Every Star Schema database has at least one dimension table. Each dimension table will be linked to a dimension value column in the fact table and will hold extra information about that value.
An example of a Star Schema
The employee dimension table may contain information such as the employee’s name, gender, address, or phone number, and may use the employee ID as a key value. A product dimension table can hold data such as the product name,manufacturing cost, color, and first-to-market date.
Characteristics of Star Schema
Because of the following characteristics, the Star Schema is ideally suited for data warehouse database design:
It builds a denormalized database that responds to queries rapidly.
It has a flexible architecture that can be readily updated or added to as the database grows and the development cycle progresses.
It gives a design equivalent to how end-users normally think of and utilize the internet.
Advantages of a Star Schema
End-users and applications can easily comprehend Star Schemas and the applications can easily navigate through them. The consumer can immediately evaluate massive, multidimensional data sets using a well-designed schema.
The following are the key benefits of Star Schemas in a decision-support environment:
Simpler queries: In comparison to other join logic needed to collect data from a transactional schema that is well normalized, Star Schema’s join logic is a breeze.
Simplified business reporting logic: The Star Schema simplifies basic business reporting logic, such as “as-of reporting and period-over-period”, when compared to a transactional schema that is heavily standardized.
Feeding cubes: All OLAP systems employ the Star Schema to efficiently create OLAP cubes. In reality, most OLAP systems offer a ROLAP mode of operation that allows you to use a Star Schema as a source without having to create a cube structure.


Shortcomings of a Star Schema
Inflexible and lacks data integrity in a highly denormalized Schema state.
Many-to-many relationships aren't supported within business entities.
One-off inserts and updates can result in data anomalies.
How Lyftrondata helps
Lyftrondata, a modern data fabric platform solution, helps to load the data in Star Schema, provides real-time data access and enables users to query them with simple ANSI SQL. With Lyftrondata, enterprises can build data pipelines in minutes and shorten time to insights by 75%, with the power of modern cloud computing of Snowflake and Spark.
Lyftrondata eliminates the time spent by engineers building data pipelines manually and makes data instantly accessible to analysts with simple and standard ANSI SQL. Its pre built connectors automatically deliver data to warehouses in normalized, ready-to-query schemas and provide full search on the data catalog.

Are you unsure about the best option for setting up your data infrastructure?
